2.1 Qu’est-ce que le Web ?
Le World Wide Web – ou Web (toile d’araignée mondiale) désigne un système donnant accès à un ensemble de données (page, image, son, vidéo) reliées par des liens hypertextes et accessibles sur le réseau internet. Quels sont ses principes de fonctionnement ?
Repères historiques
- Connaître les étapes du développement du Web.
- 1965 : invention et programmation du concept d’hypertexte par Ted Nelson ;
- 1989 : mise au point du Web au CERN par le Britannique Sir Timothy John Berners-Lee et le Belge Robert Cailliau ;
- 1993 : mise dans le domaine public, disponibilité du premier navigateur Mosaic ;
- 1995 : apparition des langages permettant les sites Web interactifs (langage JavaScript) et dynamiques (langage PHP) ;
Quelques clarifications
Qu’est ce qu’un hypertexte ?
Un hypertexte est un texte qui se lit de manière non linéaire, dans lequel on peut « naviguer ».
Un lien hypertexte permet le passage d’un élément du document que l’on parcourt vers un autre élément du même document, d’une autre page sur le même site ou encore d’une page d’un autre site web.
Internet ou Web ?
Eh non ! Internet, c’est un réseau de réseaux. Le Web, c’est l’ensemble des pages Web que l’on trouve sur internet. Lorsque vous utilisez Whatsapp ou Viber, vous n’êtes pas sur le Web, mais vous utilisez bien internet.
Pour naviguer sur le Web, il faut bien sûr être connecté à internet. Mais ce n’est pas (et de très loin) la seule façon d’utiliser internet.
Client et serveur
Un client, en informatique, c’est le programme qui demande une ressource à un autre programme, qui est un serveur. Le serveur reçoit la requête du client et y répond.
En temps normal, lorsque vous naviguez sur le Web (comme maintenant), le client, c’est votre navigateur (Firefox, Chrome 😒 ou Internet Explorer 😖). Lorsque vous voulez afficher une page, votre navigateur demande au serveur qui héberge cette page de bien vouloir la lui communiquer. Le serveur envoie donc la page au client, qui l’affiche.
Les adresses Web
- Décomposer l’URL d’une page.
Les ressources du Web (pages HTML, images, vidéo, etc…) se trouvent dans des dossiers, sur les disques durs de serveurs. Les serveurs sont des ordinateurs faisant tourner un programme appelé « serveur HTTP » (ou serveur web). Ce programme est à l’écoute des requêtes des clients (le logiciel de navigation que vous utilisez) qui se connecte à lui pour lui demander une ressource.
Une adresse web comme www.exemple.com désigne un dossier précis situé sur un serveur précis, unique au monde. Ce dossier contient les ressources (les différents fichiers et sous-dossiers) permettant d’afficher le site.
Arborescence d’un dossier
L’arborescence d’un dossier est une représentation en arbre du contenu d’un dossier. Le dossier atteint par l’URL www.exemple.com (URL pour Uniform Ressource Locator) est appelé le dossier racine. Il est symbolisé par un « / ».
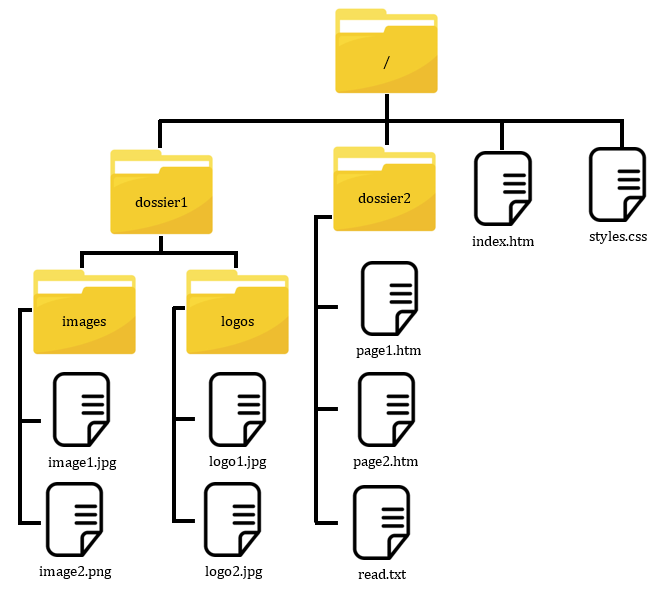
Dans l’exemple ci-dessus, le dossier racine contient deux sous-dossiers (dossier1 et dossier2) ainsi que deux fichiers (index.html et styles.css). Le sous-dossier dossier1 contient lui-même deux sous-dossiers contenant chacun deux fichiers.
En l’absence d’indication contraire, le fichier qui sera ouvert par défaut est le fichier index.html. S’il n’y en a pas, vous allez avoir un problème …
Naviguer dans l’arborescence
Pour accéder à la page 1 du site (fichier page1.htm du dossier dossier2), l’adresse absolue à rentrer dans le navigateur sera :
www.exemple.com/dossier2/page1.htm
Si, bien sûr ! Et en général, l’utilisateur ne le fait jamais. Mais si, sur notre page d’accueil, on veut faire un lien vers cette page, il faudra utiliser cette adresse dans notre code. Et puis maintenant, vous êtes capable de lire une adresse web lorsque vous naviguez sur un site. 😊
Oui ! Mais cela ne fait pas partie de l’adresse web. Il s’agit du protocole utilisé pour dialoguer avec le serveur. Et c’est ce qu’on va voir tout de suite ! Mais avant, un petit exercice !
URL d’un fichier
Vous voulez, depuis votre propre site Web, créer un lien vers la page 2 du site www.exemple.com et vers le logo 1 du même site.
Donner les adresses de ces deux fichiers.
Les protocoles HTTP et HTTPS
- Reconnaître les pages sécurisées.
Très bonne question ! Un protocole c’est un ensemble de règles qui définit la manière dont on va communiquer.
Par exemple, lorsqu’on prend un appel au téléphone, on dit généralement « Allô ? ». Cela signifie que vous avez pris l’appel et que vous êtes prêt à écouter. On finit généralement la conversation par certains termes (au revoir, salut, …) pour bien marquer que la conversation est terminée et que vous allez raccrocher.
Le protocole HTTP
Entre un navigateur qui souhaite avoir accès à une ressource du Web et un serveur Web qui héberge cette ressource, il y a également des règles précises qui sont définies par le protocole HTTP (HyperText Transfer Protocol). De nombreux autres procoles existent et servent dans d’autres contextes.
En ajoutant http:// devant une URL, le navigateur précise que la communication se fait par le protocole HTTP. Comme c’est presque toujours le cas par défaut, il n’y a même plus besoin de préciser cela explicitement au navigateur. Il le comprend et l’ajoute de lui-même.
Le protocole HTTPS
Il s’agit presque du même protocole, à un détail près : la communication serveur – client est cryptée. Cela signifie que seul le serveur peut comprendre ce que dit le client et inversement.
Imaginons la situation suivante : vous vous êtes connecté sur un réseau public (à l’aéroport ou dans un restaurant, par exemple) et vous décidez, grâce à un petit logiciel adéquat appelé un sniffeur, d’« écouter » les échanges entre les clients utilisés sur ce réseau et les serveurs avec qui ils communiquent.
Une autre personne décide à ce moment là de consulter ses mails. Il doit donc communiquer son nom d’utilisateur et son mot de passe au site qui héberge sa messagerie. Si l’échange n’est pas crypté, vous serez peut-être capable de le lire et de vous en servir ensuite pour vous connecter à sa messagerie.
Le fait que la communication soit cryptée ne vous empêche pas de suivre les échanges client – serveur, mais vous serez incapable de les comprendre (sauf à les décrypter, mais là, c’est une autre histoire... 😇)
L’adresse d’un site Web qui permet l’échange de donnée via le protocole HTTPS commence par https:// . Il y a souvent un petit cadenas à gauche de la barre d’adresse du navigateur pour indiquer que le site est sûr.