3.5 De l’informatique à l’intelligence artificielle
Jusqu’au début du XXe siècle, les machines traitant l’information sont limitées à une ou quelques tâches prédéterminées (tisser grâce à un ruban ou des cartes perforées, …). Turing a été le premier à proposer le concept de machine universelle qui a été matérialisé dix ans plus tard avec les premiers ordinateurs.
Ordinateur
- Analyser des documents historiques relatifs au traitement de l’information et à son automatisation.
- Recenser les différentes situations de la vie courante où sont utilisés les ordinateurs, identifier lesquels sont programmables et par qui (thermostat d'ambiance, smartphone, box internet, ordinateur de bord d'une voiture, …).
Ce qu’en dit Wikipédia
Un ordinateur est un système de traitement de l’information programmable qui fonctionne par la lecture séquentielle [c’est-à-dire dans un ordre défini] d’un ensemble d'instructions, organisées en programmes. Ces instructions lui font exécuter des opérations logiques et arithmétiques. Sa structure physique actuelle fait que toutes les opérations reposent sur la logique binaire et sur des nombres formés à partir de chiffres binaires.
Les données à manipuler sont acquises soit par la lecture de mémoires, soit en provenance de périphériques (souris, clavier, mesures physiques, lecteur de mémoire, carte réseau…). Une fois utilisés, ou manipulés, les résultats sont écrits soit dans des mémoires, soit dans des composants qui peuvent transformer une valeur binaire en une action physique (écriture sur une imprimante ou sur un moniteur, accélération ou freinage d'un véhicule, changement de température d'un four…).
Un ordinateur est constitué a minima d’un processeur, d’une mémoire vive et de périphériques d’entrée et de sortie (sans quoi il ne peut pas recevoir d’information et/ou ne peut rien en faire).
Exemples d’ordinateur
1. Donner des exemples d’ordinateurs utilisés dans la vie quotidienne, autres que les exemples évidents que sont les ordinateurs classique (PC…) et les téléphones portables.
2. Le thermostat d’une chaudière peut-il être considéré comme un ordinateur ? (Attention, la réponse attendue est : « ça dépend », à vous de développer de quoi ça dépend 😊)
3. Commenter cet extrait du programme officiel : « Recenser les différentes situations de la vie courante où sont utilisés les ordinateurs, identifier lesquels sont programmables (…) ».
Correction
Fichiers
- Savoir distinguer les fichiers exécutables des autres fichiers sous un système d’exploitation donné.
- Connaître l’ordre de grandeur de la taille d’un fichier image, son, vidéo.
- Savoir calculer la taille en octets d’une page de texte (en ASCII et non compressé).
Bit & octet
Comme cela a été mentionné dans la citation de Wikipédia, les ordinateurs actuels ne sont capables de travailler, au niveau fondamental, qu’avec des 0 et des 1.
Un bit est l’unité élémentaire de mémoire et ne peut prendre que deux valeurs, 0 et 1.
Les bits (b) sont regroupés en octet (o) – ou byte (B) en anglais – qui est un groupe de 8 bits.
Un octet peut donc prendre 28 soit 256 valeurs différentes (de 0 à 255).
Ainsi, un nombre entier dont la valeur peut varier entre 0 et 255 nécessitera 1 octet pour être stocké.
Fichiers exécutables
Dans un ordinateur, l’information est stockée en mémoire sous forme de fichiers. Il faut bien distinguer, pour votre propre sécurité 🤓, les fichiers qui contiennent de l’information « simple », c’est-à-dire destinée uniquement à être lue et/ou modifiée sans affecter l’état de votre ordinateur – par exemple des images, du texte, et autres types de données – des fichiers qui contiennent des instructions exécutables par votre machine et capables de modifier son état (les fichiers .exe sous Windows, mais il n’y a pas qu’eux, loin s’en faut).
Fichiers de données
Les données les plus courantes, utilisées par tout un chacun, sont les textes, les images, les sons et les vidéos. Les descriptions qui suivent sont extrêmement succintes.
Texte
Un texte brut (c’est-à-dire non mis en forme) est une suite de caractères, et à chaque caractère est assigné un nombre selon un table de codage prédéfinie (il existe plein de standard de codage de caractères, mais petit-à-petit, malgré les efforts considérables de Microsoft et d’Apple pour freiner le processus de standardisation, un encodage est en train de s’imposer comme universel : l’utf-8).
L’ASCII (American Standard Code for Information Interchange) est un standard permettant d’encoder des caractères sur 7 bits (soit 128 caractères possibles – incluant certains caractères spéciaux et certains caractères de ponctuation).
Ce système n’est plus utilisé car il ne permet pas d’encoder les caractères accentués – on ne peut écrire correctement qu’en anglais, mais venant des États-Uniens, on n’en attendait pas moins 😊.
Cependant de nombreux systèmes d’encodage de caractères en 8 bits (256 caractères possibles) partagent les mêmes 128 premiers caractères de l’ASCII.
Retenez que, en général, un caractère est stocké sur un octet et donc qu’un texte brut (non formaté) aura une taille d’un octet par caractère (retour à la ligne compris).
Son
Le stockage numérique d’un son se fait par une mesure du signal électrique généré par le micro à intervalle de temps très petit (44100 fois par seconde est une valeur standard). Chaque mesure correspond à un nombre qui est ensuite transformé en nombre binaire.
Le stockage d’un fichier son se fait, en général, sous forme compressée. L’ensemble des mesures correspondant au fichier son sont transformées par un algorithme qui réduit leur taille, soit en perdant un peu de qualité de son (compression destructive – exemple : mp3) soit sans perte (compression sans perte – exempe : flac).
Ceci permet de réduire sensiblement la taille du fichier (typiquement d’un facteur 3 à 5 pour le mp3, ou d’un facteur 2 pour le flac).
Image
Une image est découpé en pixels (picture element)*. À chaque pixel est associé un niveau de rouge, un niveau de vert et un niveau de bleu (les trois couleurs primaires de la synthèse additive permettant, par leur combinaison, de recréer toutes les couleurs). Chaque niveau est stocké (en général) sur un octet, et peut donc prendre 256 valeurs. Donc un pixel d’une image en couleur non compressée nécessite 3 octets pour être stocké.
Comme pour le son, le stockage d’une image ne se fait quasiment jamais en format non compressée. Il existe des formats de compression destructif – de l’information va être perdue (exemple : jpg) – et des formats non destructifs – sans perte (exemple : png).
Une toute petite image compte environ 40.000 pixels, alors qu’une image issue d’un appareil photo professionnel en compte plus de 50 millions.
*Il existe une autre manière de coder une image, qui consiste à décrire mathématiquement les formes présentes. Ce sont les images vectorielles, utilisées lorsqu’on souhaite faire des graphiques, logos, schéma, etc. Cette méthode n’est pas adaptée pour des photos.
Vidéo
Si vous avez compris comment on code le son et l’image, je crois que vous pouvez deviner seul comment on code une vidéo… 😊
Taille des différents type de données
Il faut connaître quelques ordres de grandeurs de la taille de ces fichiers.
| Type de fichiers | Taille (ordre de grandeur) |
|---|---|
| Image | 10 ko – 10 Mo |
| Son (mp3) | 1 à 2 Mo par minute |
| Vidéo basse résolution | 10 à 15 Mo par minute |
| Vidéo full HD (h.264) | 30 à 50 Mo par minute |
| 1 page de texte (~ 2500 caractères) | 2,5 ko |
Bien entendu, ces tailles peuvent être très variables en fonction du format de fichier et du type de compression choisi. Mais si un site vous propose de télécharger la dernière saison de votre série préférée et vous annonce une taille de fichier de 50 Mo, méfiez-vous…
Programmes & bugs
- Étant donné un programme très simple, proposer des jeux de données d’entrée permettant d’en tester toutes les lignes.
- Corriger un algorithme ou un programme buggé simple.
Un programme peut comporter jusqu’à plusieurs centaines de millions de lignes de code, ce qui rend très probable la présence d’erreurs appelées bugs (ou bogues – terme recommandé par la Délégation générale à la langue française et aux langues de France – mais ce mot, tant à l’écrit qu’à l’oral, est laid et je ne l’emploierai pas). Ces erreurs peuvent conduire un programme à avoir un comportement inattendu et entraîner des conséquences graves.
Voici quelques extraits de l’article de Wikipédia sur les bugs informatiques
Ce qu’en dit Wikipédia
En informatique, un bug est un défaut de conception d’un programme informatique à l'origine d'un dysfonctionnement.
Les bugs peuvent amener les logiciels à tenter d’effectuer des opérations impossibles à réaliser (exceptions) : division par zéro, recherche d'informations inexistantes. Ces opérations - qui ne sont jamais utilisées lors de fonctionnement correct du logiciel - déclenchent un mécanisme à la fois matériel et logiciel qui met alors hors service le logiciel défaillant, ce qui provoque un crash informatique ou un déni de service.
Un des bugs les plus chers de l’Histoire
L'échec du vol inaugural de la fusée Ariane 5 en 1996 a pour origine un défaut dans les appareils d'avionique de la fusée, appareils utilisés avec succès pendant plusieurs années sur la fusée Ariane 4. Lors du décollage, l’accélération d’Ariane 5, 5 fois plus fortes que celles d'Ariane 4, généra une valeur dépassant les limites prévues par le logiciel, ce qui a provoqué le plantage de l’ordinateur qui calculait la position de la fusée en fonction de son accélération. Aveuglé, le pilote automatique perdit le contrôle de la fusée, et un dispositif de sécurité provoqua son autodestruction quelques secondes après le décollage. 💸
Le débugage d’un logiciel consiste à analyser son fonctionnement dans un grand nombre de situations. Pour faciliter ce processus, les logiciels sont conçus à partir de fonctions plus ou moins indépendantes, chaque fonction pouvant être testée séparément.
Il y a des bugs bien plus complexes qu’une faute de frappe dans un code ! 😅 Un logiciel peut ne pas planter mais ne pas faire exactement ce qui lui est démandé. En langage de programmation de bas niveau, ces erreurs peuvent être extrêmement difficiles à déceler (se jouant, par exemple, au niveau de l’allocation mémoire, du processeur, etc.).
Correction de bugs
Voici quelques lignes de codes dont l’objectif est de déterminer si une année A donnée est bissextile ou non.
Une année est bissextile si elle est multiple de 4, mais pas multiple de 100, sauf si elle est également multiple de 400.
Bien entendu, il est buggé ! 😊
A = 2020
if A%4 == 0 : # si le reste de la division A÷4 vaut 0
bissextile = True
elif A%100 == 0 :
bissextile = False
elif A%400 == 0 :
bissextile = True
if bissextile :
print ("L’année", A, "est bissextile")
else :
print ("L’année", A, "n’est pas bissextile")
1. Proposez quelques valeurs d’années permettant de tester le bon fonctionnement du logiciel.
2. Corriger le ou les bugs trouvés.
Correction
Intelligence artificielle
- Analyser des documents relatifs à une application de l’intelligence artificielle.
- Utiliser une courbe de tendance (encore appelée courbe de régression) pour estimer une valeur inconnue à partir de données d’entraînement.
Mais qu’est-ce que c’est ?
L’intelligence artificielle est un terme employé à tort et à travers, souvent pas des personnes ne sachant qu’approximativement de quoi elles parlent.
Et pour cause… le concept est plutôt nébuleux. 😏
Voici quelques extraits de l’article de Wikipédia sur ce sujet.
Définition
L'intelligence artificielle (IA) est « l’ensemble des théories et des techniques mises en œuvre en vue de réaliser des machines capables de simuler l’intelligence humaine »
Elle correspond donc à un ensemble de concepts et de technologies plus qu'à une discipline autonome. Certaines instances, notamment la CNIL (Commission Nationale Informatique et Libertés), relevant le peu de précision dans la définition de l'IA, introduisent ce sujet comme « le grand mythe de notre temps ».
Le terme « intelligence artificielle » est défini par l’un de ses créateurs, Marvin Lee Minsky, comme « la construction de programmes informatiques qui s’adonnent à des tâches qui sont, pour l’instant, accomplies de façon plus satisfaisante par des êtres humains car elles demandent des processus mentaux de haut niveau tels que : l’apprentissage perceptuel, l’organisation de la mémoire et le raisonnement critique »
Intelligence artificielle forte
Ce concept fait référence à une machine capable non seulement de produire un comportement intelligent, notamment de modéliser des idées abstraites, mais aussi d’éprouver une impression d'une réelle conscience, de « vrais sentiments » (quoi qu’on puisse mettre derrière ces mots), et « une compréhension de ses propres raisonnements ». De telles machines n’existent pas (encore ?).
Intelligence artificielle faible
Cette notion constitue une approche pragmatique d’ingénieur : chercher à construire des systèmes de plus en plus autonomes (pour réduire le coût de leur supervision), des algorithmes capables de résoudre des problèmes d’une certaine classe, etc. Mais, cette fois, la machine ne fait que simuler l'intelligence.
Il faut également distinguer plusieurs termes qui sont parfois confondus :
- L'apprentissage profond (deep learning) est un ensemble de méthodes d'apprentissage automatique tentant de modéliser avec un haut niveau d’abstraction des données. La machine détermine elle-même quelles sont les critères de modélisation.
- L'apprentissage automatique (machine learning) est un champ d'étude de l'intelligence artificielle qui se fonde sur des approches mathématiques et statistiques pour donner aux ordinateurs la capacité d'« apprendre » à partir de données, c'est-à-dire d'améliorer leurs performances à résoudre des tâches sans être explicitement programmés pour chacune.

Apprentissage automatique
Pour réaliser un apprentissage automatique, il faut fournir à l’ordinateur une grande quantité de données représentatives et de qualité.
Pour entraîner une IA à reconnaître des visages sur des photos, il faut lui fournir une grande quantité de photos et lui indiquer s’il y a des visages et où ils se trouvent le cas échéant.
En utilisation des corrélations de données, les algorithmes vont déterminer d’eux-même quels sont les critères à retenir pour déterminer l’existence et la position d’un visage sur une photo.
Déterminer ces critères dans un algorithme direct seraient très complexes.
La machine pourra par la suite détecter les visages dans une photo, mais jamais avec un taux de réussite de 100 %.
Correlations de données
Vous êtes un algoritme de machine learning (allez, un peu d’imagination 😊). On vous alimente avec des données. Une des étapes de votre apprentissage consiste à repérer les données corrélées et à trouver la relation mathématique qui les lient.
C’est ce que vous allez faire dans cet exercice, en utilisant les données regroupées dans ce fichier CSV concernant 4 grandeurs $*a*$, $*b*$, $*c*$ et $*d*$ (peu importe ce qu’elles représentent – de toute façon vous n’êtes pas capable de les comprendre 😁).
Correction
Utiliser des prédictions d’une IA
- À partir de données, par exemple issues d’un diagnostic médical fondé sur un test, produire un tableau de contingence afin de calculer des fréquences de faux positifs, faux négatifs, vrais positifs, vrais négatifs. En déduire le nombre de personnes malades suivant leur résultat au test.
Lorsqu’une « prédiction » est réalisée à partir de données, ou plus simplement lorsqu’un test est réalisé, il est fréquent que cette prédiction ne soit pas fiable à 100 %.
Lorsqu’un test (au sens large) est réalisé, il y a quatre cas de figure :
- Le résultat du test est positif et ce résultat correspond bien à la réalité.
- Le résultat du test est positif mais il est erroné (faux positif).
- Le résultat du test est négatif et ce résultat correspond à la réalité.
- Le résultat du test est négatif mais il est erroné (faux négatif).
La fiabilité d’un test est sa probabilité de détecter un cas positif. Par exemple, un test COVID fiable à 99 % signifie que si une personne qui a le COVID se fait tester, le résultat du test a 99 % de chance d’être positif (le 1 % restant correspond aux faux négatif).
La spécificité d’un test est sa probabilité de ne pas être positif lorsque il devrait être négatif. Par exemple, un test COVID spécifique à 95 % signifie que si une personne qui n’a pas le COVID se fait tester, le résultat du test a 95 % de chance d’être négatif (les 5 % restant correspondent aux faux positifs).

Les résultats d’une série de tests peuvent être notés dans un tableau de contingence qui permettent d’estimer la fiabilité et la spécifité du test.
Détection de spam
De nombreux fournisseurs de boîtes mails appliquent un algorithme de détection de spam pour classer automatiquement les mails reçus dans un dossier spam s’ils sont considérés comme tel.
Un test est donc appliqué à chaque message, le résultat du test étant spam ou courrier légitime
Bien-sûr, ce test n’est pas infaillible et il arrive qu’un message spam ne soit pas détecté comme tel, et inversement, il arrive que qu’un message légitime soit considéré comme du spam.
Il est possible pour l’utilisateur de corriger le résultat des tests de l’algorithme.
Voici des données concernant un échantillon de 1000 messages : 128 d’entre eux ont été considérés comme du spam, parmi lesquels 12 étaient en fait des message légitimes.
Parmi les 872 messages détectés comme légitimes, 65 étaient en fait du spam.
1. Résumer ces résultats dans le tableau de contingence ci-dessous.
| détectés comme spam | détectés comme légitime | |
|---|---|---|
| messages spam | ||
| messages légitimes |
2. Calculer la fiabilité et la spécificité de cet algorithme
3. Dans un échantillon de 1500 messages, l’algorithme détecte 80 spams. Donner une estimation du nombre réel de spam dans cet échantillon. Si vous trouvez les calculs trop compliqués, vous pouvez prendre une spécificité de 100 % 😊
Il est parfois nécessaire de prioriser la fiabilité sur la spécificité ou inversement.
4. Qu’en est-il pour un algorithme de détection des spams ? Et pour un algorithme de détection de mélanome malin à partir de photo ?
Correction
1. Tableau de contingence.
| détectés comme spam | détectés comme légitime | |
|---|---|---|
| messages spam | 116 | 65 |
| messages légitimes | 12 | 807 |
2. Fiabilité : 181 spams réels (116 + 65) dont 116 détectés comme spam, soit une fiabilité de 116÷181 = 0,641 (64,1 %)
Spécificité : 819 messages légitimes, dont 807 détectés comme légitimes, soit une spécificité de 807÷819 = 0,985 (98,5 %)
3. On a 4 inconnues nommées $*a*$, $*b*$, $*c*$ et $*d*$ telles qu’indiquées dans le schéma ci-dessous.
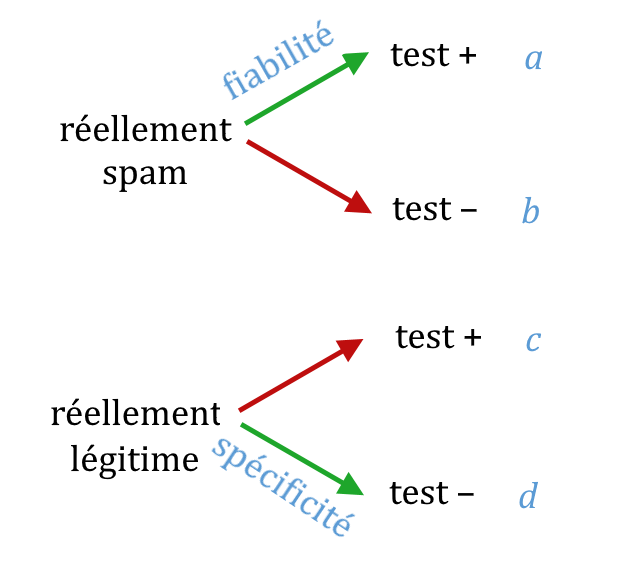
Appelons $*N*$ le nombre total de message (ici, $*N*$ = 1500) et $*n*$ le nombre de messages détectés comme spam (ici 80).
Notons $*f*$ la fiabilité du test (ici $*f*$ = 0,64) et $*s*$ la spécificité du test (ici 0,985).
On peut écrire 4 équations :
(1) $*a + c = n*$
(2) $*b + d = N – n*$
(3) $* a = (a + b)·f*$
(4) $* d = (c + d)·s*$
Il suffit (!) de résoudre ce système d’équations pour répondre au problème. Avec un peu de méthode, ça ne fait pas énormément de calculs.
On va chercher à exprimer $*b*$, $*c*$, et $*d*$ en fonction de $*a*$. On commence par réduire trouver une expression de ces trois inconnues.
D’après (1) : $*c = n- a*$
d’après (2) : $*b = N - n - d*$
d’après (4) : $*d = cs - ds = \dfrac{cs}{1-s} = c\gamma*$
en posant $*\gamma = \dfrac s{1-s}*$
On se sert ensuite de ces résultats dans l’équation (3) :
$µ \begin{aligned}
a &= (a + N - n - d)·f \\
a &= (a + N – n – c\gamma)·f \\
a &= (a + N – n – (n – a)\gamma)·f
\end{aligned} µ$
À ce stade, on est arrivé à notre objectif. On a une seule équation en fonction de $*a*$. Il ne reste plus qu’à la simplifier.
$µ \begin{aligned}
a &= (a + N – n – n\gamma + a\gamma)f \\
\frac af &= a(1+\gamma) + N – n(1+\gamma)
\end{aligned} µ$
Posons $*\delta = 1 + \gamma*$, juste pour simplifier l’écriture,
$µ \begin{aligned}
\frac af - a\delta &= N – n\delta \\
a(\frac 1f - \delta) &= N – n\delta \\
a &= \frac {N – n\delta}{\frac 1f - \delta}
\end{aligned} µ$
Le reste des variables vient très simplement :
$* b = a\dfrac {1-f}f *$
$*c = n - a*$
$* d = (n-a)\gamma*$
Après un petit calcul, on trouve :
$*a*$ = 58,8 (nombre de spams détectés comme tel)
$*b*$ = 33,0 (nombre de faux négatifs)
$*c*$ = 21,1 (nombre de faux positif)
$*d*$ = 1387 (nombre de messages légitimes détectés comme tel)
Remarque : lorsque j’ai rédigé l’exercice, je ne me suis pas rendu compte de sa difficulté… 😁
Je ne vous poserai pas une telle question en devoir. 😅
4. Pour un algorithme de détection des spams, il vaut mieux avoir du spam non filtré plutôt qu’un message important mis dans les spams. Il vaut donc mieux prioriser la spécificité
Par contre, pour un algorithme de détection de mélanome, il vaut mieux avoir un faux positif (donc une fausse alerte) plutôt qu’un faux négatif (un mélanome non détecté qui ne sera pas pris à temps pour être soigné). Il faut donc prioriser la fiabilité.